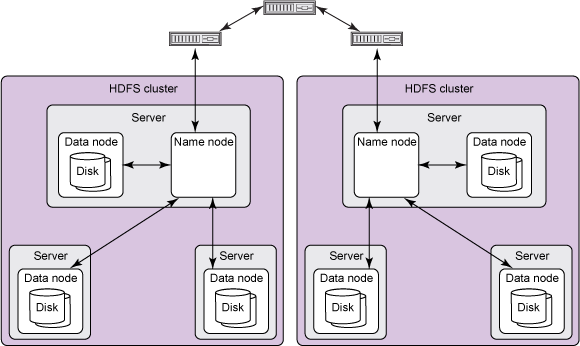
In the previous blog “Smattering of HDFS“, we learnt that “The NameNode is a Single Point of Failure for the HDFS Cluster”. Each cluster had a single NameNode and if that machine became unavailable, the whole cluster would become unavailable until the NameNode is restarted or brought up on a different machine. Now in this blog, we will learn about resolving the failure issue of NameNode.
Issues that arise when NameNode fails/crashes-
The metadata for the HDFS like Namespace Information, block information etc, when in use needs to be stored in main memory, but for persistence storage, it is to be stored in disk. The NameNode stores two types of information:
1. in-memory fsimage – It is the latest and updated snapshot of the Hadoop filesystem namespace.
2. editLogs – It is the sequence of changes made to the filesystem after NameNode started.
The total availablity of HDFS cluster is decreased in two major ways:
1. In the case of a machine crash, the cluster would become unavailable until the machine is restarted.
2. In case of maintenance task to be carried on NameNode machine, cluster downtime would happen.
StandBy NameNode – the solution to NameNode failure
In HDFS High Availability feature, it provides a facility of running two NameNodes in the same cluster. There is an active-passive architecture for NameNode, that is, if NameNode goes down, within a few seconds, the passive NameNode also known as Standby NameNode comes up. At any point in time, one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast fail over if necessary.
For Namespace Information backup, the fsImage is stored along with the editLog. The editLog is like the journal ledger of NameNode. Through it, the in-memory fsImage can be reconstructed. So, it is needed to make the backup of editLog .
In Gen2 Hadoop architecture, there is a facility of Quorum Journal Manager(QJM) which is a set of atleast 3 machines known as journal nodes, where editLogs are stored for backup. To minimize the time to start the passive NameNode in case of active NameNode crash, the standby machine available is pre-configured and ready to take over the role of NameNode.
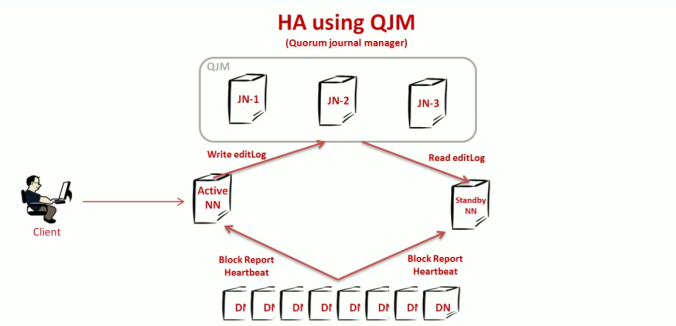
The Standby NameNode keeps reading the editLogs from the journal nodes and keeps itself updated. This configuration makes Standby ready to take up the active NameNode role in case of failure. All the DataNodes are configured to send the Block Report to both of the NameNodes. Thus, the Standby NameNode becomes active in case of NameNode failure in a short duration of time.